Enterprise-Grade PII Detectie & Anonimisering
Regex-patronen voor gestructureerde data, beproefde ML-modellen voor namen. Transparante, controleerbare resultaten op Hetzners ISO 27001-gecertificeerde servers in Duitsland.
Waarom Kiezen voor anonym.legal
Deterministische patroondetectie
Regex-patronen voor gestructureerde data (e-mails, SSN, creditcards) geven 100% reproduceerbare resultaten. ML-gebaseerde NER voor namen en organisaties biedt hoge consistentie. Volledig controleerbaar voor compliance.
Leer meer over onze technologie →Hetzner Duitsland, ISO 27001 gecertificeerd
Alle verwerking vindt plaats in de ISO 27001-gecertificeerde datacenters van Hetzner in Duitsland. Uw gegevens blijven in de EU zonder verrassingen met betrekking tot jurisdictie.
Bekijk beveiligingsdetails →Token-gebaseerde Prijzen die U Begrijpt
Betaal voor wat u gebruikt met ons transparante tokensysteem. Gratis laag omvat 200 tokens (~15-18 pagina's/maand). Geen verborgen kosten, geen verrassingen.
Bekijk prijzen →Hoe Het Werkt
Vier eenvoudige stappen om gevoelige gegevens in uw documenten te beschermen
Upload of Plak
Voer uw tekst in via onze webinterface, API of Office Add-in
Analyseer
Onze regex-engine detecteert 285+ PII-entiteitstypen in 48 talen
Beoordeel
Zie precies wat er is gedetecteerd met vertrouwensscores
Anonimiseer
Pas uw gekozen anonimisering methode toe en download de resultaten
AI-integratie met Privacybescherming
Verbind uw AI-tools zoals Cursor en Claude Desktop terwijl u uw gevoelige gegevens veilig houdt met automatische PII-anonimisering.
Your AI Tool
(Cursor, Claude)
MCP Server
(Anonymizes PII)
AI Processes
(Safe data only)
Restore Values
(Optional)
De MCP Server fungeert als een privacy schild tussen uw AI-tools en gevoelige gegevens. Het detecteert en anonimiseert automatisch PII voordat het naar AI wordt verzonden, en herstelt vervolgens de oorspronkelijke waarden in de reacties—waardoor AI nooit uw echte gegevens ziet.
Naadloze AI-toolintegratie
Werkt met Cursor, Claude Desktop en andere MCP-compatibele tools
Privacy-eerst Architectuur
AI verwerkt alleen geanonimiseerde gegevens—oorspronkelijke PII verlaat nooit uw controle
Omkeerbare Anonimisering
Tokenisatie stelt u in staat om oorspronkelijke waarden te herstellen wanneer nodig
Zelfde Token Prijzen
Maakt gebruik van uw bestaande tokenbalans—geen extra kosten
Ondersteunde AI-tools:
Beschikbaar op Pro- en Business-plannen. Upgrade om te ontgrendelen.
Verwerk Documenten Veilig
Maximale privacy met veilige bestandsverwerking. Documenten blijven op uw apparaat — alleen geëxtraheerde tekst wordt verzonden voor analyse.
Drag & Drop
(Your files)
Local Processing
(On your device)
Analyze & Anonymize
(Text only)
Save Result
(Stay local)
De Desktop App verwerkt documenten volledig op uw apparaat. Bestanden worden lokaal gelezen, alleen de geëxtraheerde tekst wordt verzonden voor analyse, en uw documenten blijven privé.
Veilige Bestandsverwerking
Documenten blijven op uw computer — alleen geëxtraheerde tekst wordt naar onze veilige API verzonden
Versleutelde Lokale Opslag
Geschiedenis, presets en versleutelingssleutels opgeslagen in uw versleutelde lokale kluis
Sleep- en Neerzetinterface
Eenvoudige, intuïtieve workflow—sleep bestanden en ontvang direct resultaten
Meerdere Indelingen
PDF, DOCX, TXT en meer—verwerk elk documenttype
Beschikbaar voor:
Detecteer namen, e-mails, telefoonnummers, creditcards, SSN's, IBAN's, IP-adressen en meer in meerdere categorieën.
Volledige ondersteuning voor 48 talen, waaronder Engels, Duits, Spaans, Frans en 43 meer met RTL-ondersteuning voor Arabisch, Hebreeuws, Perzisch en Urdu. Aangedreven door spaCy, Stanza en XLM-RoBERTa NLP-engines.
Vervangen, Redigeren, Hashen (SHA-256), Versleutelen (AES-256-GCM) of Maskeren—kies de beschermingsmethode die bij uw gebruiksgeval past.
Betrouwbaarheid van ondernemingskwaliteit met monitoring, geautomatiseerde back-ups en procedures voor incidentrespons.
Gratis compliance- en beveiligingsgidsen
Download deskundige bronnen die uw organisatie helpen gevoelige gegevens te beschermen en te voldoen aan compliance-eisen.
Bekijk het in actie
Bekijk hoe anonym.legal gevoelige gegevens in realtime beschermt in al uw favoriete tools.
Latest Insights
Research, guides, and analysis on data privacy
Real-Time PII Prevention Saves $2.2M
IBM found a $2.2M cost difference between prevention and detection. Here's the math that makes real-time PII interception non-optional for security teams.
GDPR Art. 32: AI Tools PII Monitoring
Enterprise compliance teams need quantitative evidence of AI tool PII controls. Network DLP misses browser AI interactions.
Real-Time PII Prevention for AI Data Leaks
When an employee types a customer name into ChatGPT, the data leaves organizational control in real-time. Post-hoc DLP cannot un-ring this bell.
Explore anonym.legal
Klaar om Uw Gegevens te Beschermen?
Begin met onze gratis laag—200 tokens per cyclus, geen creditcard vereist.
About this page
We update this page when our platform or the law changes.
Read our founder note for how we work.
Each change shows up in the timestamp at the top.
Related reading
We follow these rules
- GDPR (EU 2016/679).
- ISO/IEC 27001:2022.
- NIS2 (EU 2022/2555).
- HIPAA safe harbor under 45 CFR § 164.514(b)(2).
Our promise
We do not sell your data.
We do not train models on your text.
We store your files in Germany.
You can delete your account at any time.
You own your work.
Where we run
Our company HQ is in Saarbrücken, Germany. Our servers run in Hetzner's Falkenstein datacenter.
Hetzner holds ISO 27001 certification.
All data stays in the EU.
Backups run every day.
Need help?
Email support@anonym.legal.
We reply within one business day.
How we test
We run a full check suite on every release.
Each surface gets its own sweep script and report.
Human reviewers spot-check the output each week.
We track recall and precision on a labelled set.
Bad runs block the deploy.
What we never do
- We never sell your information to third parties.
- We never train models on what you upload.
- We never keep your work after you delete it.
- We never share keys with any outside firm.
- We never run ads inside the product.
Plans in plain words
We sell credits, not seats.
One credit covers one short job.
Long jobs use a few credits each.
You can top up at any time.
Unused credits roll over each month.
Read the plans page for current rates.
Who built this
A small team of engineers and lawyers built this.
We ship from Europe and work in the open.
Our founder note spells out why we started.
Where to start
- Open the web app and try a sample file.
- Learn how credits get counted.
- See current plans and limits.
- Meet the team behind the product.
How the parts fit
A browser add-on cleans text inside Chrome.
A Word plug-in handles drafts in Office.
A small desktop tool works on whole folders.
An agent protocol link feeds large models safely.
All four share one core engine and one rule set.
Words from our team
We started this work after a lunch about cookies.
One friend kept getting odd ads on her phone.
We asked why a court file leaked through a draft.
We sketched the first build on a napkin that week.
By month three we had a tiny demo for a friend.
She used it on her first case the next day.
Common questions we hear
Can the tool read scanned PDFs? Yes, with OCR.
Does it work on long files? Yes, in small chunks.
Can I roll my own rule set? Yes, save it as a preset.
Does it run offline? The desktop build runs offline.
Do you keep my files? No, the cloud build wipes after each run.
Will it learn from my work? No, we never train on inputs.
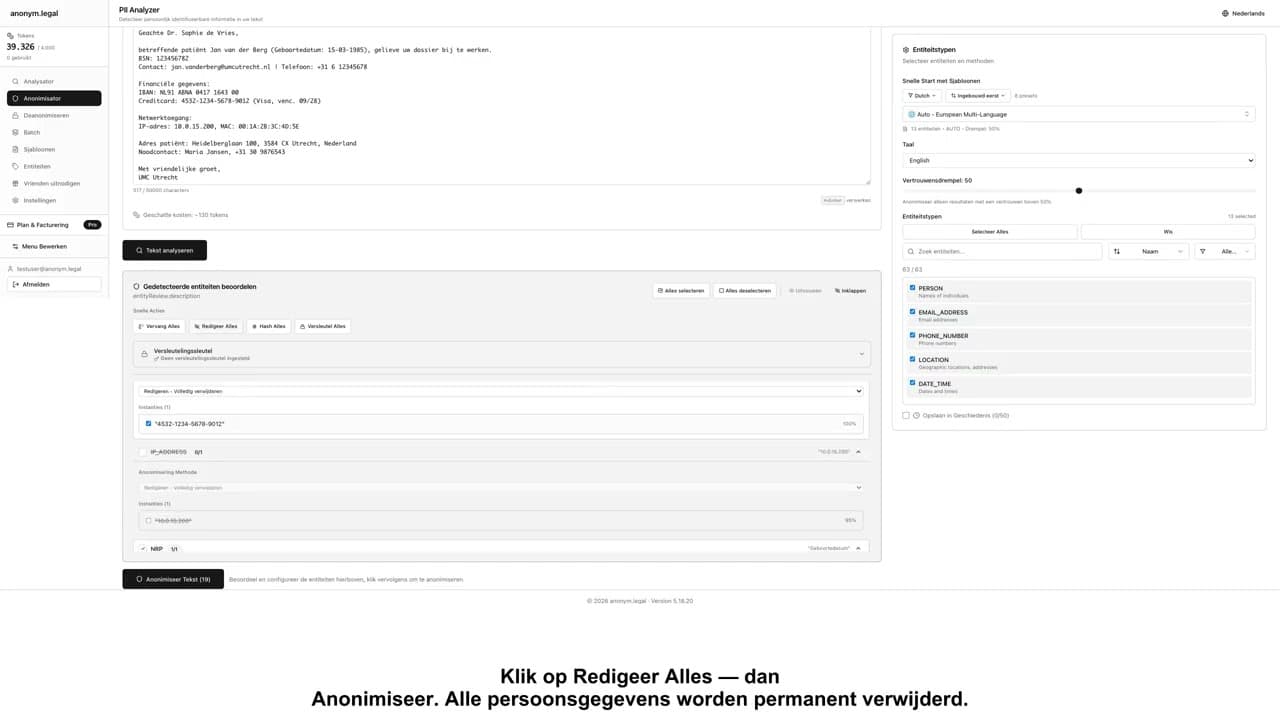
A short tour of the workflow
Upload a file or paste a snippet of prose.
Pick the entities you want gone from the draft.
Choose a method: replace, mask, hash, encrypt, or redact.
Press run and watch the side panel show each hit.
Skim the result and tweak any rule that misfired.
Save the cleaned file or send it to a teammate.