기업 수준의 PII 탐지 및 익명화
구조화된 데이터를 위한 정규식 패턴, 이름을 위한 검증된 ML 모델. 독일 Hetzner ISO 27001 인증 서버에서 투명하고 감사 가능한 결과 제공.
왜 anonym.legal을 선택해야 할까요
결정론적 패턴 감지
구조화된 데이터(이메일, SSN, 신용카드)용 정규식 패턴은 100% 재현 가능한 결과를 제공합니다. 이름과 조직을 위한 ML 기반 NER은 높은 일관성을 제공합니다. 규정 준수를 위해 완전히 감사 가능합니다.
우리 기술에 대해 알아보기 →Hetzner 독일, ISO 27001 인증
모든 처리는 독일의 Hetzner ISO 27001 인증 데이터 센터에서 이루어집니다. 귀하의 데이터는 EU 내에 유지되며 예기치 않은 관할권 문제는 없습니다.
보안 세부정보 보기 →이해할 수 있는 토큰 기반 가격
투명한 토큰 시스템으로 사용한 만큼만 지불합니다. 무료 요금제에는 200토큰(~15-18페이지/월)이 포함됩니다. 숨겨진 수수료 없음, 놀라움 없음.
가격 보기 →작동 방식
문서의 민감한 데이터를 보호하는 네 가지 간단한 단계
업로드 또는 붙여넣기
웹 인터페이스, API 또는 Office 추가 기능을 통해 텍스트를 입력하세요.
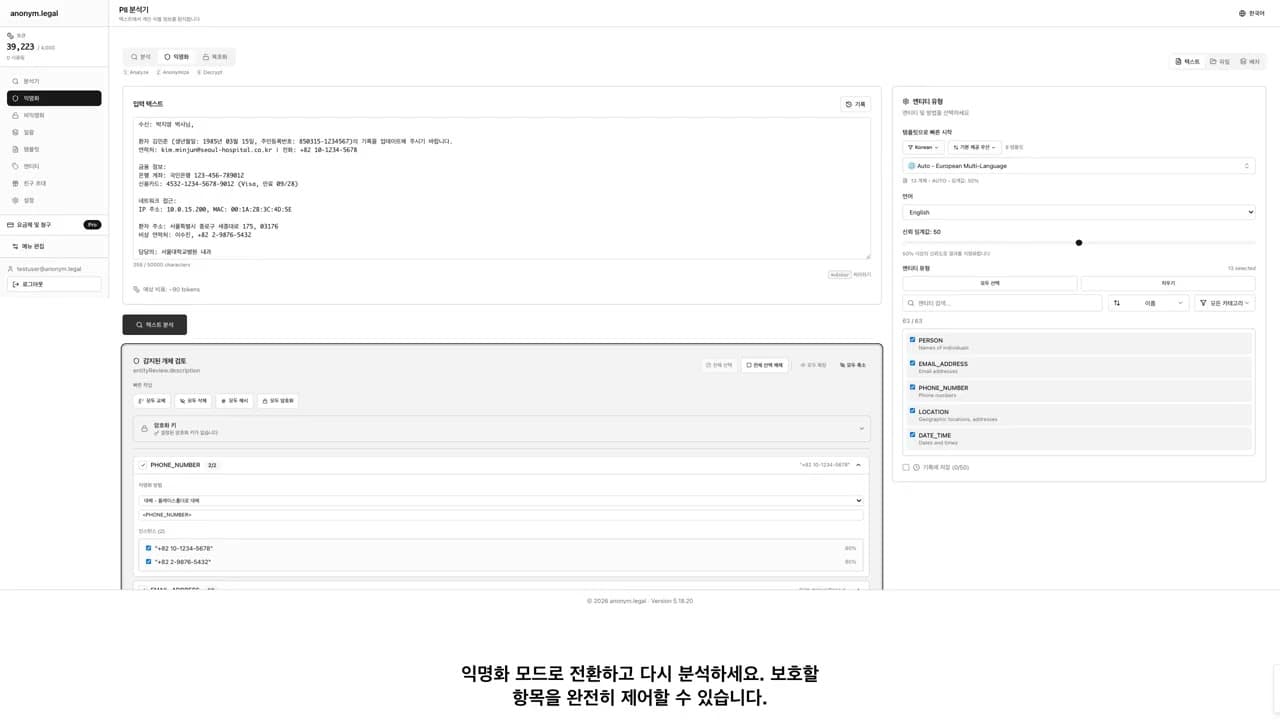
분석
우리의 정규 표현식 엔진은 48개 언어에서 50개 이상의 PII 엔터티 유형을 탐지합니다.
검토
신뢰도 점수와 함께 탐지된 내용을 정확히 확인하세요.
익명화
선택한 익명화 방법을 적용하고 결과를 다운로드하세요.
개인 정보 보호와 함께하는 AI 통합
Cursor 및 Claude Desktop과 같은 AI 도구를 연결하면서 민감한 데이터를 자동으로 PII 익명화로 안전하게 보호합니다.
Your AI Tool
(Cursor, Claude)
MCP Server
(Anonymizes PII)
AI Processes
(Safe data only)
Restore Values
(Optional)
MCP 서버는 귀하의 AI 도구와 민감한 데이터 간의 개인 정보 보호 장치 역할을 합니다. AI에 전송하기 전에 PII를 자동으로 탐지하고 익명화하며, 응답에서 원래 값을 복원하여 AI가 귀하의 실제 데이터를 보지 않도록 합니다.
원활한 AI 도구 통합
Cursor, Claude Desktop 및 기타 MCP 호환 도구와 함께 작동
개인 정보 보호 우선 아키텍처
AI는 익명화된 데이터만 처리—원래 PII는 귀하의 통제를 벗어나지 않습니다
되돌릴 수 있는 익명화
토큰화로 필요할 때 원래 값을 복원할 수 있습니다
동일한 토큰 가격
기존 토큰 잔액을 사용—추가 비용 없음
지원되는 AI 도구:
전문 및 비즈니스 요금제에서 사용 가능. 업그레이드하여 잠금 해제하세요.
문서를 안전하게 처리하세요
안전한 파일 처리로 최대한의 개인 정보 보호. 문서는 귀하의 장치에 남아 있으며, 추출된 텍스트만 분석을 위해 전송됩니다.
Drag & Drop
(Your files)
Local Processing
(On your device)
Analyze & Anonymize
(Text only)
Save Result
(Stay local)
데스크탑 앱은 문서를 전적으로 귀하의 장치에서 처리합니다. 파일은 로컬에서 읽히며, 추출된 텍스트만 분석을 위해 전송되고 귀하의 문서는 비공개로 유지됩니다.
안전한 파일 처리
문서는 귀하의 컴퓨터에 남아 있으며, 추출된 텍스트만 우리의 안전한 API로 전송됩니다.
암호화된 로컬 저장소
기록, 프리셋 및 암호화 키가 귀하의 암호화된 로컬 금고에 저장됩니다.
드래그 앤 드롭 인터페이스
간단하고 직관적인 워크플로—파일을 드래그하고 즉시 결과를 얻습니다.
다양한 형식
PDF, DOCX, TXT 등—모든 문서 유형 처리
사용 가능 플랫폼:
이름, 이메일, 전화번호, 신용카드, SSN, IBAN, IP 주소 등 여러 카테고리에서 탐지합니다.
영어, 독일어, 스페인어, 프랑스어 및 아랍어, 히브리어, 페르시아어, 우르두어에 대한 RTL 지원을 포함하여 48개 언어를 완벽하게 지원합니다. spaCy, Stanza 및 XLM-RoBERTa NLP 엔진으로 구동됩니다.
대체, 삭제, 해시(SHA-256), 암호화(AES-256-GCM) 또는 마스킹—귀하의 사용 사례에 맞는 보호 방법을 선택하세요.
모니터링, 자동 백업 및 사고 대응 절차를 갖춘 기업 수준의 신뢰성.
무료 컴플라이언스 및 보안 가이드
전문가 자료를 다운로드하여 조직이 민감한 데이터를 보호하고 컴플라이언스 요건을 충족하도록 지원하세요.
실제 동작 보기
즐겨 사용하는 도구 전반에서 anonym.legal이 민감한 데이터를 실시간으로 보호하는 모습을 확인해 보세요.
Latest Insights
Research, guides, and analysis on data privacy
Real-Time PII Prevention Saves $2.2M
IBM found a $2.2M cost difference between prevention and detection. Here's the math that makes real-time PII interception non-optional for security teams.
GDPR Art. 32: AI Tools PII Monitoring
Enterprise compliance teams need quantitative evidence of AI tool PII controls. Network DLP misses browser AI interactions.
Real-Time PII Prevention for AI Data Leaks
When an employee types a customer name into ChatGPT, the data leaves organizational control in real-time. Post-hoc DLP cannot un-ring this bell.
Explore anonym.legal
About this page
We update this page when our platform or the law changes.
Read our founder note for how we work.
Each change shows up in the timestamp at the top.
Related reading
We follow these rules
- GDPR (EU 2016/679).
- ISO/IEC 27001:2022.
- NIS2 (EU 2022/2555).
- HIPAA safe harbor under 45 CFR § 164.514(b)(2).
Our promise
We do not sell your data.
We do not train models on your text.
We store your files in Germany.
You can delete your account at any time.
You own your work.
Where we run
Our company HQ is in Saarbrücken, Germany. Our servers run in Hetzner's Falkenstein datacenter.
Hetzner holds ISO 27001 certification.
All data stays in the EU.
Backups run every day.
Need help?
Email support@anonym.legal.
We reply within one business day.
How we test
We run a full check suite on every release.
Each surface gets its own sweep script and report.
Human reviewers spot-check the output each week.
We track recall and precision on a labelled set.
Bad runs block the deploy.
What we never do
- We never sell your information to third parties.
- We never train models on what you upload.
- We never keep your work after you delete it.
- We never share keys with any outside firm.
- We never run ads inside the product.
Plans in plain words
We sell credits, not seats.
One credit covers one short job.
Long jobs use a few credits each.
You can top up at any time.
Unused credits roll over each month.
Read the plans page for current rates.
Who built this
A small team of engineers and lawyers built this.
We ship from Europe and work in the open.
Our founder note spells out why we started.
Where to start
- Open the web app and try a sample file.
- Learn how credits get counted.
- See current plans and limits.
- Meet the team behind the product.
How the parts fit
A browser add-on cleans text inside Chrome.
A Word plug-in handles drafts in Office.
A small desktop tool works on whole folders.
An agent protocol link feeds large models safely.
All four share one core engine and one rule set.
Words from our team
We started this work after a lunch about cookies.
One friend kept getting odd ads on her phone.
We asked why a court file leaked through a draft.
We sketched the first build on a napkin that week.
By month three we had a tiny demo for a friend.
She used it on her first case the next day.
Common questions we hear
Can the tool read scanned PDFs? Yes, with OCR.
Does it work on long files? Yes, in small chunks.
Can I roll my own rule set? Yes, save it as a preset.
Does it run offline? The desktop build runs offline.
Do you keep my files? No, the cloud build wipes after each run.
Will it learn from my work? No, we never train on inputs.
A short tour of the workflow
Upload a file or paste a snippet of prose.
Pick the entities you want gone from the draft.
Choose a method: replace, mask, hash, encrypt, or redact.
Press run and watch the side panel show each hit.
Skim the result and tweak any rule that misfired.
Save the cleaned file or send it to a teammate.