エンタープライズグレードのPII検出と匿名化
構造化データ用のRegexパターン、名前用の実績あるMLモデル。ドイツのHetzner ISO 27001認定サーバーで透明で監査可能な結果を提供。
なぜanonym.legalを選ぶのか
決定論的パターン検出
構造化データ(メール、SSN、クレジットカード)用のRegexパターンは100%再現可能な結果を提供。名前と組織用のML基盤NERは高い一貫性を提供。コンプライアンスのために完全に監査可能。
私たちの技術について学ぶ →Hetzner ドイツ、ISO 27001認定
すべての処理は、ドイツのHetznerのISO 27001認証データセンターで行われます。あなたのデータはEU内に留まり、予期しない管轄問題はありません。
セキュリティの詳細を見る →理解できるトークンベースの料金
透明なトークンシステムで使用した分だけ支払います。無料プランには200トークン(約15-18ページ/月)が含まれています。隠れた料金はなく、驚きもありません。
料金を見る →仕組み
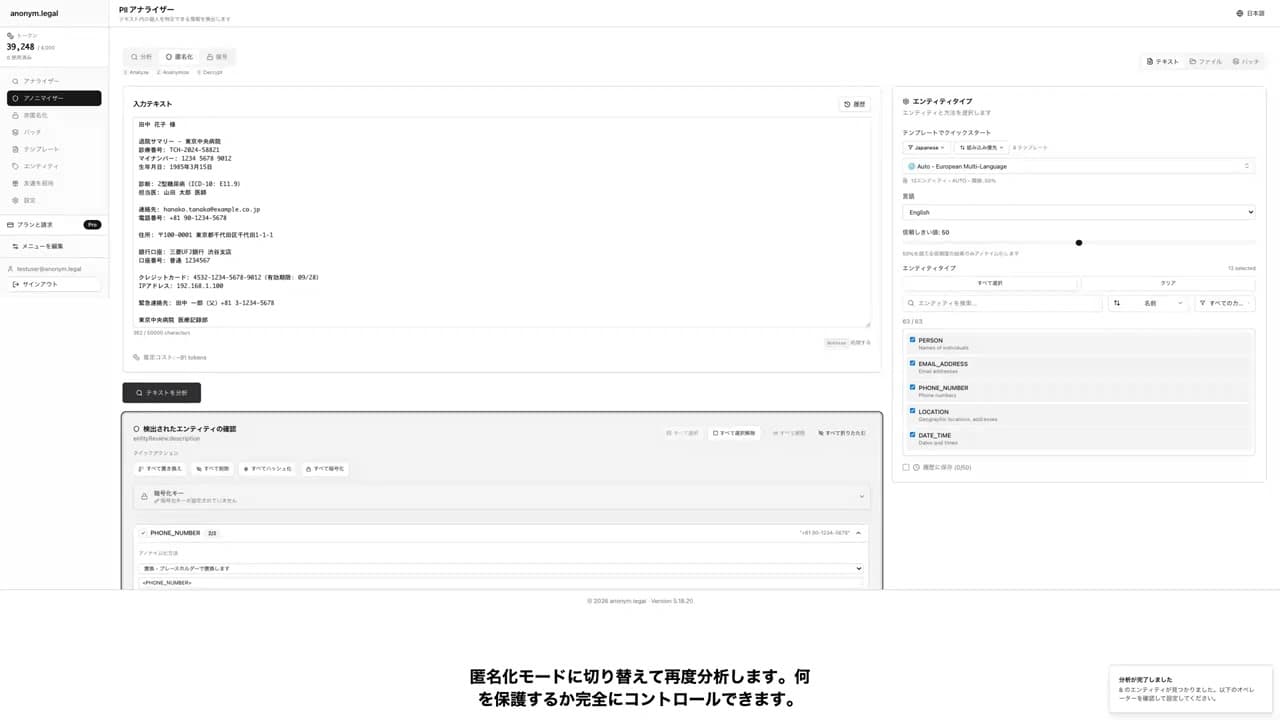
ドキュメント内の機密データを保護するための 4 つの簡単なステップ
アップロードまたは貼り付け
ウェブインターフェース、API、または Office アドインを介してテキストを入力します
分析
私たちの正規表現エンジンが 48 言語で 50 以上の PII エンティティタイプを検出します
レビュー
検出された内容を信頼スコアと共に正確に確認します
匿名化
選択した匿名化方法を適用し、結果をダウンロードします
プライバシー保護を伴うAI統合
CursorやClaude DesktopなどのAIツールを接続し、敏感なデータを自動的にPII匿名化で安全に保ちます。
Your AI Tool
(Cursor, Claude)
MCP Server
(Anonymizes PII)
AI Processes
(Safe data only)
Restore Values
(Optional)
MCPサーバーは、AIツールと敏感なデータの間のプライバシーシールドとして機能します。AIに送信する前にPIIを自動的に検出して匿名化し、応答で元の値を復元します—AIがあなたの実データを見ることはありません。
シームレスなAIツール統合
Cursor、Claude Desktop、その他のMCP対応ツールと連携
プライバシー優先のアーキテクチャ
AIは匿名化されたデータのみを処理—元のPIIはあなたの制御を離れません
可逆的な匿名化
トークン化により、必要に応じて元の値を復元できます
同じトークン料金
既存のトークン残高を使用—追加費用はありません
サポートされているAIツール:
プロおよびビジネスプランで利用可能。アップグレードしてロックを解除します。
ドキュメントを安全に処理
安全なファイル処理で最大のプライバシー。ドキュメントはあなたのデバイスに留まり、抽出されたテキストのみが分析のために送信されます。
Drag & Drop
(Your files)
Local Processing
(On your device)
Analyze & Anonymize
(Text only)
Save Result
(Stay local)
デスクトップアプリは、完全にあなたのデバイス上でドキュメントを処理します。ファイルはローカルで読み込まれ、抽出されたテキストのみが分析のために送信され、あなたのドキュメントはプライベートに保たれます。
安全なファイル処理
ドキュメントはあなたのコンピュータに留まり、抽出されたテキストのみが私たちの安全なAPIに送信されます
暗号化されたローカルストレージ
履歴、プリセット、暗号化キーはあなたの暗号化されたローカルボールトに保存されます
ドラッグ&ドロップインターフェース
シンプルで直感的なワークフロー—ファイルをドラッグして結果を瞬時に得る
複数のフォーマット
PDF、DOCX、TXTなど—任意のドキュメントタイプを処理
対応プラットフォーム:
名前、メールアドレス、電話番号、クレジットカード、SSN、IBAN、IPアドレスなど、複数のカテゴリにわたって検出します。
英語、ドイツ語、スペイン語、フランス語、アラビア語、ヘブライ語、ペルシャ語、ウルドゥー語を含む48言語を完全にサポート。spaCy、Stanza、XLM-RoBERTa NLPエンジンによって提供されています。
置換、削除、ハッシュ(SHA-256)、暗号化(AES-256-GCM)、またはマスク—あなたのユースケースに合った保護方法を選択してください。
監視、自動バックアップ、インシデント対応手順を備えたエンタープライズグレードの信頼性。
コンプライアンスとセキュリティの無料ガイド
専門家によるリソースをダウンロードして、組織の機微なデータを保護し、コンプライアンス要件の遵守に役立ててください。
実際の動作を見る
anonym.legal が、お使いのさまざまなツールで機密データをリアルタイムに保護する様子をご覧ください。
Latest Insights
Research, guides, and analysis on data privacy
Real-Time PII Prevention Saves $2.2M
IBM found a $2.2M cost difference between prevention and detection. Here's the math that makes real-time PII interception non-optional for security teams.
GDPR Art. 32: AI Tools PII Monitoring
Enterprise compliance teams need quantitative evidence of AI tool PII controls. Network DLP misses browser AI interactions.
Real-Time PII Prevention for AI Data Leaks
When an employee types a customer name into ChatGPT, the data leaves organizational control in real-time. Post-hoc DLP cannot un-ring this bell.
Explore anonym.legal
About this page
We update this page when our platform or the law changes.
Read our founder note for how we work.
Each change shows up in the timestamp at the top.
Related reading
We follow these rules
- GDPR (EU 2016/679).
- ISO/IEC 27001:2022.
- NIS2 (EU 2022/2555).
- HIPAA safe harbor under 45 CFR § 164.514(b)(2).
Our promise
We do not sell your data.
We do not train models on your text.
We store your files in Germany.
You can delete your account at any time.
You own your work.
Where we run
Our company HQ is in Saarbrücken, Germany. Our servers run in Hetzner's Falkenstein datacenter.
Hetzner holds ISO 27001 certification.
All data stays in the EU.
Backups run every day.
Need help?
Email support@anonym.legal.
We reply within one business day.
How we test
We run a full check suite on every release.
Each surface gets its own sweep script and report.
Human reviewers spot-check the output each week.
We track recall and precision on a labelled set.
Bad runs block the deploy.
What we never do
- We never sell your information to third parties.
- We never train models on what you upload.
- We never keep your work after you delete it.
- We never share keys with any outside firm.
- We never run ads inside the product.
Plans in plain words
We sell credits, not seats.
One credit covers one short job.
Long jobs use a few credits each.
You can top up at any time.
Unused credits roll over each month.
Read the plans page for current rates.
Who built this
A small team of engineers and lawyers built this.
We ship from Europe and work in the open.
Our founder note spells out why we started.
Where to start
- Open the web app and try a sample file.
- Learn how credits get counted.
- See current plans and limits.
- Meet the team behind the product.
How the parts fit
A browser add-on cleans text inside Chrome.
A Word plug-in handles drafts in Office.
A small desktop tool works on whole folders.
An agent protocol link feeds large models safely.
All four share one core engine and one rule set.
Words from our team
We started this work after a lunch about cookies.
One friend kept getting odd ads on her phone.
We asked why a court file leaked through a draft.
We sketched the first build on a napkin that week.
By month three we had a tiny demo for a friend.
She used it on her first case the next day.
Common questions we hear
Can the tool read scanned PDFs? Yes, with OCR.
Does it work on long files? Yes, in small chunks.
Can I roll my own rule set? Yes, save it as a preset.
Does it run offline? The desktop build runs offline.
Do you keep my files? No, the cloud build wipes after each run.
Will it learn from my work? No, we never train on inputs.
A short tour of the workflow
Upload a file or paste a snippet of prose.
Pick the entities you want gone from the draft.
Choose a method: replace, mask, hash, encrypt, or redact.
Press run and watch the side panel show each hit.
Skim the result and tweak any rule that misfired.
Save the cleaned file or send it to a teammate.